ラズパイ+Juliusで音声認識
- 2020.08.21
- IoT

音声認識としてオープンソースで提供されているJuliusを使ってラズパイ+マイク(usbカメラ)で使ってみようと思います。
結果としては手順さえわかれば簡単に動かせますがその間に何度も詰んでいるため、Macなど他の環境で動かす際に
同じ失敗を繰り返さないためにも今回まとめておきます.(それと誰かの役にも立てば嬉しい)
以下の手順通り進めれば大体大丈夫だと思う.
以下のサイトを参考に進めていきます。
Raspberry pi3B+でjuliusを動かせるようになるまでの覚書き
・公式
https://julius.osdn.jp/index.php?q=newjulius.html
主に使ったもの
Raspberry pi 4 8gb
ロジクール ウェブカメラ
マイク接続
まずはマイク入力の設定から行っていく.
ラズパイにマイクを接続し、ターミナルからlsusbで確認する.
|
1 2 3 4 5 6 7 8 9 |
$ lsusb ↓実行結果 Bus 002 Device 001: ID 1d6b:0003 Linux Foundation 3.0 root hub Bus 001 Device 005: ID 046d:c047 Logitech, Inc. Laser Mouse M-UAL120 Bus 001 Device 004: ID 1a2c:4324 China Resource Semico Co., Ltd Bus 001 Device 003: ID 046d:0825 Logitech, Inc. Webcam C270 ←これ Bus 001 Device 002: ID 2109:3431 VIA Labs, Inc. Hub Bus 001 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub |
マイクの優先順位
接続したマイクの使用が最優先になるように設定する.
/proc/asound/modulesにオーディオデバイスの優先順位が書いてある.
|
1 2 3 4 5 |
$ sudo cat /proc/asound/modules 0 snd_bcm2835 1 snd_bcm2835 2 snd_usb_audio |
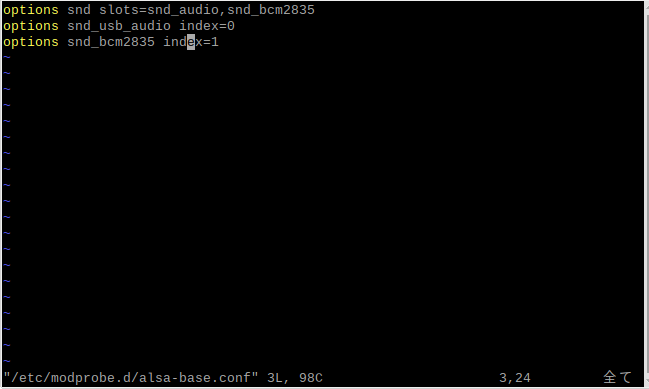
優先順位を変更するには/etc/modprobe.d/alsa-base.confを編集する.
vimで開く.
|
1 |
$ sudo vim /etc/modprobe.d/alsa-base.conf |
Vimはキーボードの「a」を入力することで挿入モードになり入力が可能になる.
挿入モードになったら「snd_usb_audio index=0」に変更する.
入力が終わったら「esc」キーを押して挿入モードを解除し、「:wq」と入力して保存して閉じる.
(「w」は保存、「q」はファイルを閉じるコマンド.ちなみに「:q!」と「!」をつけることでファイルの強制終了が可能)
設定が終わったので再読み込みをさせる.
|
1 |
$ reboot |
再度オーディオモジュールの設定を見てみる.
|
1 |
$ sudo cat /proc/asound/modules |
snd_usb_audioが最上位に来ていればOK.
|
1 2 3 |
0 snd_usb_audio 1 snd_bcm2835 2 snd_bcm2835 |
Juliusインストール
まずは編集用のディレクトリを作成.
|
1 2 |
$ mkdir julius $ cd julius |
Juliusをダウンロード.(2020/8時点でバージョンは4.5)
|
1 |
$ wget https://github.com/julius-speech/julius/archive/v4.5.tar.gz |
インストールのその前にalsaのサウンドドライバをインストールする.
(これを忘れていたせいでJuliusが動かす詰んでしまった…)
|
1 2 |
$ sudo apt-get install osspd-alsa $ sudo aptitude install libasound2-dev |
インストールできたら以下のコマンドでデバイスのカードNO,デバイスNoを固定しておく.
|
1 |
$ sudo vim ~/.profile |
ファイルを開いたら最終行に以下を追加して閉じる.
|
1 |
export ALSADEV=hw:0,0 |
そしてJuliusのインストール.
ダウンロードしたファイルを解凍してインストールする.
ただし、「./configure」を実行する際は後ろに必ず—with-mictype=alsaをつける.
これもつけ忘れるとかなり詰むので注意!
|
1 2 3 4 5 |
$ tar xvzf v4.5.tar.gz $ cd julius-4.5 $ ./configure --with-mictype=alsa $ make $ sudo make install |
音声認識パッケージの取得
ここではdictation-kitとgrammar-kitをダウンロードする.
dictation-kit:音声を認識して文字として出力する言語データが詰め込まれている.
grammar-kit:単語辞書を利用したサンプルが詰まっているイメージ.今回ほぼ使わない.
|
1 2 3 4 |
$ wget https://github.com/julius-speech/dictation-kit/archive/v4.5.zip $ wget https://github.com/julius-speech/grammar-kit/archive/v4.3.1.zip $ unzip dictation-kit-v4.5.zip $ unzip dictation-kit-v4.3.1.zip |
実行
実際に認証させてみた.
dictation-kitで試してみる.
|
1 |
$ julius -C ~/julius/dictation-kit-v4.5/main.jconf -C ~/julius/dictation-kit-v4.5/am-gmm.jconf -nostrip -input mic |
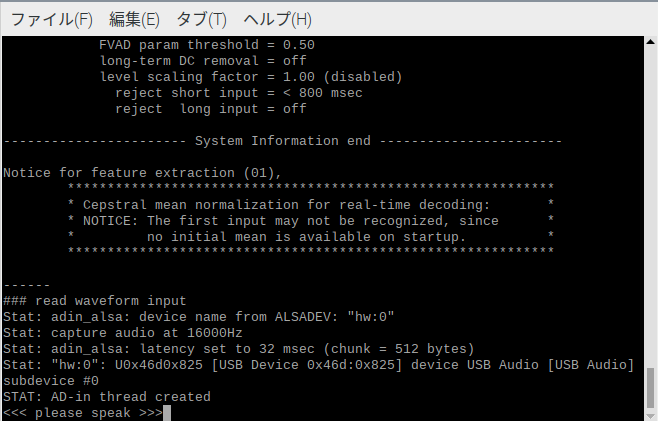
「明日は雨です。」とマイクに入力.
対面で会話する感覚で話してみた場合.
マイクからの距離も少しあるためか空耳発生.
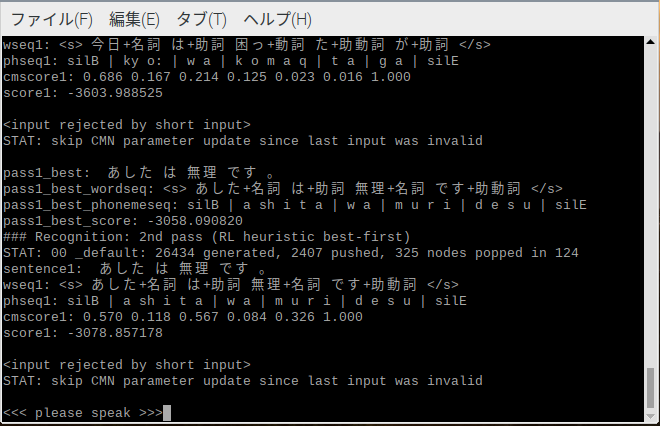
マイクに近づき少しはっきりと喋った場合.
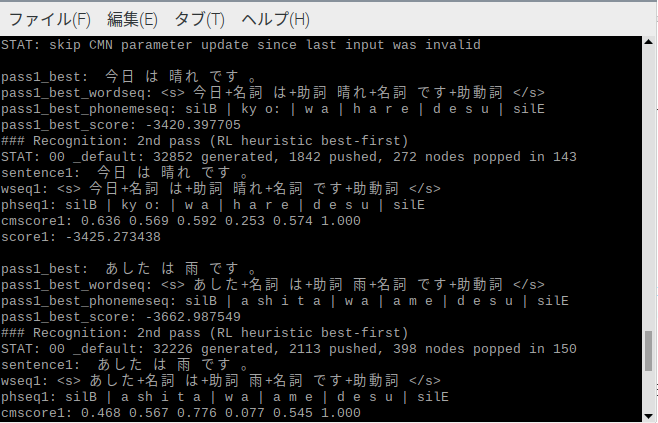
ちなみに「今日は晴れです。」もマイク入力したもの.
個人的にだけど思ったより認識は悪くないと思う.
また、Juliusコマンドに「-input rawfile」をつけることでwavファイルからも認識できた.
/grammar-kit-master/sample.wavを使用.(「りんごを3個ください。」と録音されている)
「-input」 を「mic」から「rawfile」にすると以下の様にwavファイルのパスを入力するように促される.
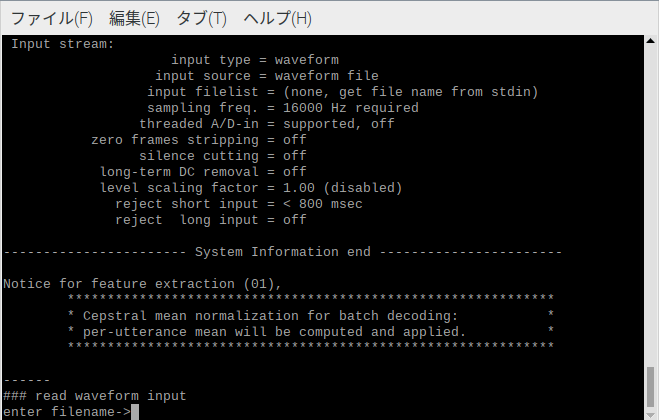
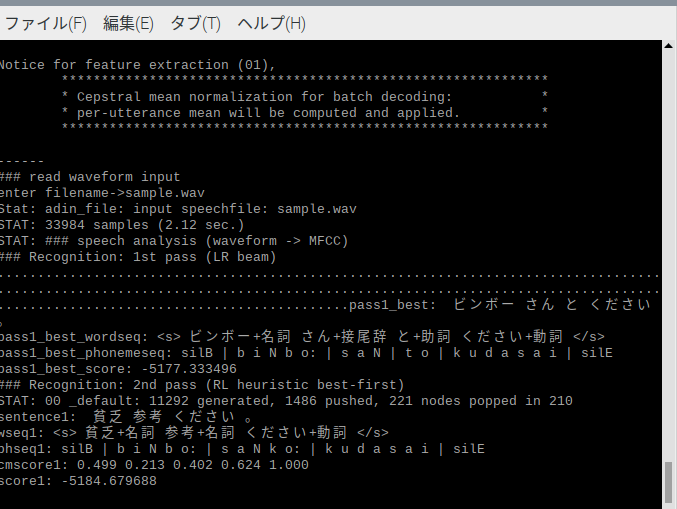
空耳発生.
使用した音声自体がノイズがかなり乗っているのでまあそんなもんかなぁといったところ.
(独自辞書向けに作られたサンプル音源でもあるためわざとだと思う)
音声ファイルの対応形式としてはThe Julius Book(第3章 音声データ入力)から引用したものを以下に載せます.
指定できるオプションなども載っているため一度眺めておくと良いかも.
.wavファイル:Microsoft WAVE形式 WAVファイル(16bit, 無圧縮PCM, monoral のみ)
ヘッダ無しRAWファイル:データ形式は signed short (16bit),Big Endian, monoral
参考: https://julius.osdn.jp/juliusbook/ja/desc_adin.html
終わりに
今回は独自辞書による音声認識は取り扱わなかったため、次回に辞書の作成方法も含めて試してみようと思う.
また、Julius内のlibjulius,libsentを静的に読み込むことでアプリに組み込むこともできるみたいなのでそれもやってみたい.
-
前の記事
![[PhotoShop]画像入りWEB用ヘッダーの作成](https://kocoffy.com/programmer_cat/wp-content/uploads/2020/08/画像ありWebバナー-150x150.jpeg)
[PhotoShop]画像入りWEB用ヘッダーの作成 2020.08.21
-
次の記事
[WordPress]LION BLOGでカテゴリー 選択ができない不具合への対応 2020.08.23