【JupyterLab】Pandasでwebページをcsv出力できるのが便利すぎる話
こんにちは. 機械学習の勉強に明け暮れるxinoです.
最近データハンドリング辺りに嚙みついていますが、その一環として「scrapy」を使ってwebスクレイピングをやってみました.(チュートリアルをまとめたので気が向いたら共有します)
scrapyってなんやねんって方はこちらを
10分で理解する Scrapy
勉強初期にお世話になりました.
これがまあまあ規模が大きく、SpiderやPipelineやら登場人物も多いため作るまでかなり時間がかかってしまいました…(その甲斐あって、Spiderを増やすだけで他サイトのクローリングも楽にできますが)
以下がスクレイピングしてcsv出力したデータです. Jupyterlabで開いてます.
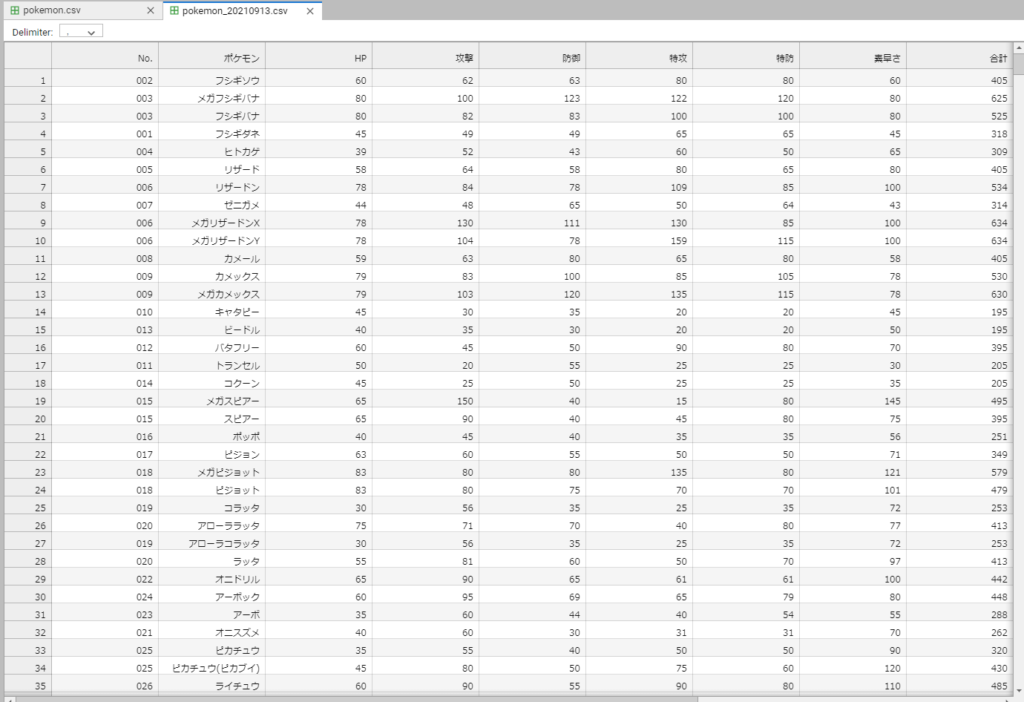
画像からは見切れていますが、タイプや重さなどの情報もポケモンの名前からリンクを辿って取得できています.
で、タイトルについてですが、ポケモンの番号から種族値までは1ページ(tableタグ)にまとまっています.
もしこれだけが欲しいんだったらpandasを使うことですぐにファイル出力することが可能です.
前置きが長くなりましたが、Pandasのread_htmlについて書いていきます.(本編の内容は薄いです)
WebサイトのHTMLから表を取得
今回取得するページはポケモン徹底攻略さんのポケモン一覧ページです.
https://yakkun.com/swsh/stats_list.htm?mode=all/
read_htmlを使うにあたって、取得対象がtable要素で囲まれている必要があります.
言い直すと、html内にあるtable要素をすべて抜き出す関数です.(今回は一つだけ)
実行
次にJupyterLab内で動かした結果を載せます.
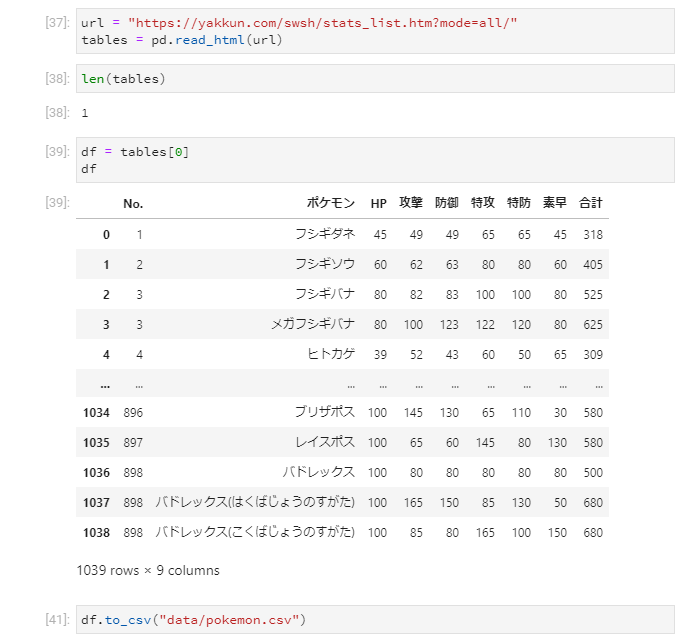
いくつtable要素を抜き出したのかはlen関数で確認できます.
今回は一つだけなので、tables[0]でDataFrameとして取得が可能です.
そしてそのままto_csvでファイル出力して終わりです.
結果
ファイルを開きます.
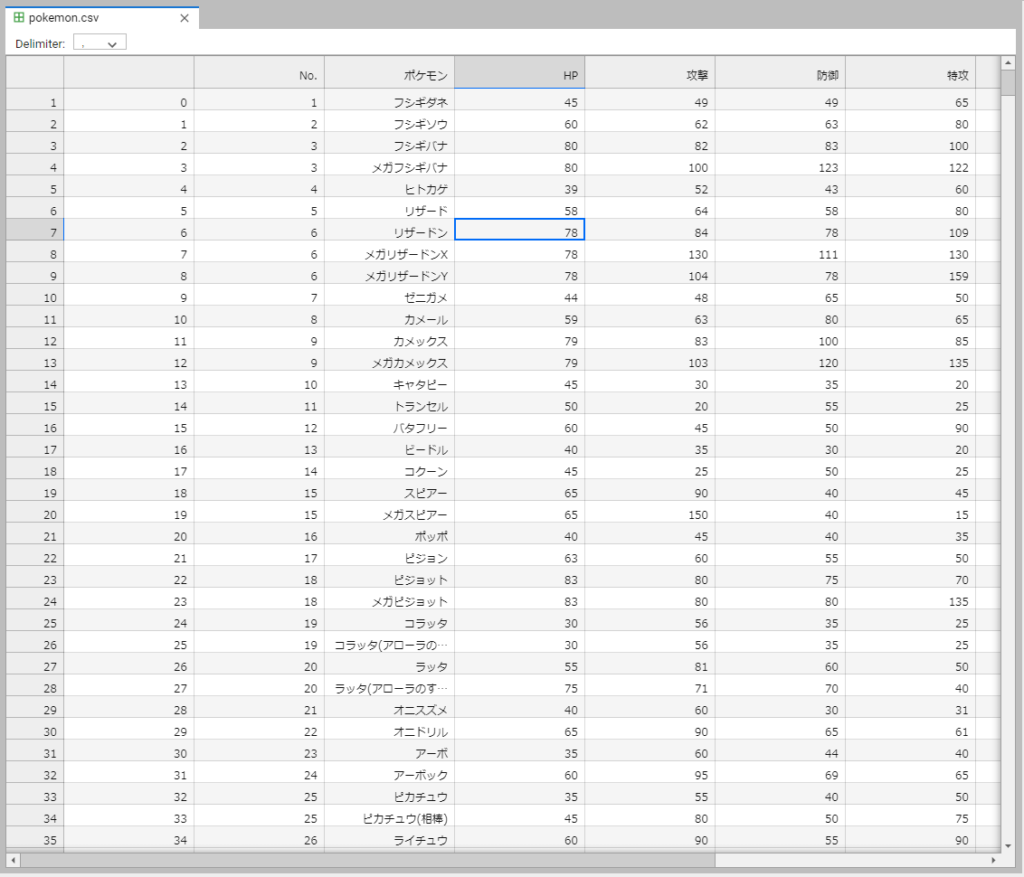
エディターでデフォルメされていますが、きれいに取れました.
ここまで5分もかかってないです.
終わりに
めちゃくちゃ早くとれて感動した勢いで書いたので、中身のない記事になりました…
ただ、この気持ちを忘れることは決してないはず…なので資格試験(もちろんその先も)にもしっかり活かしたいですね.
今回はポケモンのデータでしたが、日常的に使われている情報もtable要素としてまとめられていることが多いと思います.
「ファイル出力できる」のも大きいですが、DataFrameとして前処理してきれいにしてやれば、すぐに統計や機械学習にも活用できると思います. 別々のtable要素に情報が散漫しているなど、そのような場合にはスクレイピングが有効ですが、それとは別の選択肢としてデータ入手に役立てていきたいところ.
次は中身のあるやつ書きます.いつかは分かりませんが.
-
前の記事
【JupyterLab Desktop App】Jupyter notebookのデスクトップアプリがリリースされたので早速使ってみました 2021.10.08
-
次の記事
![[データハンドリング]特徴量、カテゴリ変数の正規化についてざっくりまとめ](https://kocoffy.com/programmer_cat/wp-content/uploads/2021/08/python_104451-150x150.png)
[データハンドリング]特徴量、カテゴリ変数の正規化についてざっくりまとめ 2021.10.29