[データハンドリング]特徴量、カテゴリ変数の正規化についてざっくりまとめ
![[データハンドリング]特徴量、カテゴリ変数の正規化についてざっくりまとめ](https://kocoffy.com/programmer_cat/wp-content/uploads/2021/08/python_104451-512x500.png)
カテゴリ変数の正規化に関しては、分類モデルであればカテゴリに分ける際に必須なのため、それなり(One-hotベクトルぐらいしか知らないが)に分かります.
が、主に入力値(特徴量)の正規化はあんまり考えずに生データを突っ込んでいたのでこれを機に調べてみました.
分かりやすく説明できる気がしないので、「完全に理解した」きっかけになったサイトなどのリンクを張りつつ、「要するに」で総括していこうかと思います。
要するに備忘録です.
ちなみに途中で載せるコードなどは資格勉強に使っている「Pythonによるデータ分析の教科書」を参考にしています.
なんで正規化するの?
ポケモンで例えるなら種族値と体重を特徴量として使う場合に、そのままだと互いにスケールが違う.
どちらかが大きければそちらの特徴量の影響を大きく受けてしまい、もう片方が軽視されてしまうのを防ぐために互いの尺度をそろえてやる必要があります.
特徴量の正規化
・分散正規化:
特徴量を平均0、分散1となる値に変換します.
$$ Y = \frac{X – μ}{σ} $$
書籍ではこう呼ばれてはいますが、数式を見る限りでは標準化を指していると思います.
具体的にどういうこと?って感じで調べてみると以下のサイトで概ね理解できました.
https://mathwords.net/hyouzyunka
要するに平均値を基準にその点数の価値(すごさ)を評価できるようにすることらしいです.
・pythonで実装:
「scikit-learn」の「preprocessing」モジュールにある「StandardScaler」
クラスを使います.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
import pandas as pd from sklearn.preprocessing import StandardScaler #DataFrameを作成する df = pd.DataFrame( { 'A':[1, 2, 3, 4, 5], 'B':[100, 200, 400, 500, 800] } ) #分散正規化のインスタンス生成 stdsc = StandardScaler() stdsc.fit(df) stdsc.transform(df) |
|
1 2 3 4 5 |
array([[-1.41421356, -1.22474487], [-0.70710678, -0.81649658], [ 0. , 0. ], [ 0.70710678, 0.40824829], [ 1.41421356, 1.63299316]]) |
・最小最大正規化:
特徴量を最小0、最大1の範囲に正規化します.(参考:https://mathwords.net/dataseikika)
$$ Y = \frac{X – x_{min}}{x_{max} – x_{min}} $$
一見すると0~1の値に変換してくれるのは便利に思えますが、例えば外れ値(他と比べて極端に値が大きいor小さい値)があると、そちらの影響を強く受けてしまうっぽいです.
・pythonで実装:
「scikit-learn」の「preprocessing」モジュールにある「MinMaxScaler」
クラスを使います
|
1 2 3 4 5 6 |
from sklearn.preprocessing import MinMaxScaler #最小最大正規化のインスタンスを生成] mmsc = MinMaxScaler() #最小最大正規化を実行 mmsc.fit(df) mmsc.transform(df) |
|
1 2 3 4 5 |
array([[0. , 0. ], [0.25 , 0.14285714], [0.5 , 0.42857143], [0.75 , 0.57142857], [1. , 1. ]]) |
カテゴリ変数のエンコーディング
ロジスティック回帰分析(分類)の場合、またポケモンで例えるなら体重と種族値を特徴量、正解値としてタイプを扱うときに「水」や「炎」などは明らかにそのままでは学習には使えないってことは想像しやすいと思います
そこで、「水」⇒「0」、「炎」⇒「1」、「草」⇒「2」…と変換することで数値として扱えるようにします.
・pythonで実装:
「scikit-learn」の「preprocessing」モジュールにある「LabelEncoder」
クラスを使います.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
##ポケモンのタイプで正規化 import pandas as pd from sklearn.preprocessing import LabelEncoder df_type = pd.DataFrame( { 'タイプ':['水', '炎', '草'] } ) #ラベルエンコーダーのインスタンスを生成 le = LabelEncoder() #ラベルのエンコーディング le.fit(df_type['タイプ']) le.transform(df_type['タイプ']) |
|
1 |
array([0, 1, 2]) |
・One-hotエンコーディング:
こちらは簡単に言えば、カテゴリ変数を0か1で表現できるようにする処理です.
例えば、「水」⇒「1,0,0」、「炎」⇒「0,1,0」、「草」⇒「0,0,1」といった感じにします.
これはカテゴリ変数の数だけ列が増え、各行に対応した列が1、それ以外の列は0で埋めます.
・pythonで実装:
「scikit-learn」の「preprocessing」モジュールにある「OneHotEncoder」クラスを使います.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
from sklearn.preprocessing import LabelEncoder, OneHotEncoder from sklearn.compose import ColumnTransformer #DataFrameをコピー df_ohe = df_type.copy() #ラベルのエンコーダのインスタンス化 le = LabelEncoder() #タイプを1,2,3に変換 df_ohe['タイプ'] = le.fit_transform(df_ohe['タイプ']) #One-hotエンコーダのインスタンス化 ohe = ColumnTransformer([("OneHotEncoder", OneHotEncoder(), [0])], remainder='passthrough') #One-hotエンコーディング ohe.fit_transform(df_ohe) |
|
1 2 3 |
array([[1., 0., 0.], [0., 1., 0.], [0., 0., 1.]]) |
ちなみにpandasでも同様のことができ、その場合は「get_dummies」関数を使います
こちらはsk-learnとは違って、DataFrameでそのまま返してくれるため便利.
やるならpandasの方がよさそうです.
|
1 2 |
df_onehot = pd.get_dummies(df_type.loc[:,'タイプ'],prefix='タイプ') df_onehot |
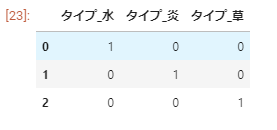
実行結果も大変わかりやすいです.
終わりに
特徴量、カテゴリ変数の正規化についてざっくりまとめてみました.
資格の勉強の一環としてやってみましたが、内容はさておき自分で腑に落ちる言葉で書き連ねるのも良いですね.
書き終わるとすっきりします.
当初、勉強するならインプットとアウトプットはしっかり分けようって考えでやっていましたが、互いに期間が空くとせっかく詰め込んだ知識も着地点が見つからずにどこかへ行ってしまうような感覚であんまり効率よくなかったです.
次は分類モデルについて、ちまちまとまとめてみようかと思います…
-
前の記事
【JupyterLab】Pandasでwebページをcsv出力できるのが便利すぎる話 2021.10.12
-
次の記事

【機械学習】勾配降下法についてざっくりまとめ【Python】 2021.11.12